Introduction
The landscape of database technology is rapidly evolving, and Oracle Database 23ai's introduction of vector search capabilities marks a pivotal moment for developers who have honed their skills within the realm of traditional relational databases. As we stand on the cusp of integrating advanced AI-driven functionalities directly into the database, there is an unprecedented opportunity to harness the power of generative AI within familiar SQL environments.

In this post, I'll walk you through the key components that make this integration possible. We'll see the VECTOR datatype, which lies at the heart of vector search, and the fact that Oracle allows you to effectively create and store vectors within your Oracle database. We'll also dip our toes into the new vector indexes that optimize these searches, as well as the powerful similarity searching functions that enable semantic searches within your applications. Lastly, we'll touch on some of the administrative and diagnostic capabilities that Oracle has provided to ensure your vector-based applications run smoothly. Whether you're a seasoned Oracle developer or DBA, this post aims to equip you with the knowledge and confidence to start building the next generation of intelligent applications.
What is Oracle Database 23ai Vector Search?
Oracle Database 23ai's introduction of vector search capabilities represents a major evolution [a paradigm shift if you will] in database technology, enabling developers to implement advanced applications like semantic search directly within the database using standard SQL enhanced with new vector-specific functions. This development significantly lowers the barrier for Oracle database developers, allowing them to leverage powerful vector search capabilities without needing to step far outside their familiar SQL environment.
While this advancement may seem like a revolutionary shift, it's also a natural extension of Oracle's tradition of integrating sophisticated algorithms directly into the database. Just as Oracle previously embedded machine learning algorithms within the database to keep data processing close to the data itself, this new vector search capability brings the power of large language models (LLMs) to bear on data stored within the database. By utilizing vector embeddings—numerical representations of data that capture semantic meaning in a high-dimensional space—developers can now perform tasks such as identifying similar items, clustering data based on meaning, or conducting complex searches that go far beyond traditional keyword matching, all within the familiar framework of Oracle SQL.
With vector search integrated into Oracle Database 23ai, developers can now build applications that understand and respond to the underlying meaning of the data, rather than just its surface-level characteristics or keyword style similarity searching. For instance, a semantic search application can retrieve documents, images, or other data that are contextually similar to a query, even if they don't share the same exact words or features. This opens the door to a wide range of use cases, from more intuitive search engines within enterprise systems to personalized recommendation engines that can offer users more relevant content based on their past interactions. The ability to implement these capabilities using standard SQL means that developers can integrate them seamlessly into existing Oracle-based systems, making the power of vector search accessible without the need for additional infrastructure or complex coding.
Why use Oracle AI Vector Search
Oracle AI Vector Search offers significant benefits by allowing semantic searches on unstructured data to be combined with relational searches on business data within a single system. This integration eliminates the need for a specialized vector database, reducing data fragmentation across multiple systems. It also supports Retrieval Augmented Generation (RAG), a generative AI technique that combines large language models with private business data, providing accurate responses to natural language queries without exposing private data.
For example, a table can now have both relational data and vector data that is used for generative AI applications. This setup allows for queries that seamlessly integrate standard SQL with vector data by including vector distance functions in your query to retrieve results based on both relational and vector data. Overall, Oracle AI Vector Search enhances efficiency and accuracy in handling and querying diverse data types.
The Primary Use Case:
The primary use case for Vector Search inside the Oracle Database is to enable integrated and efficient querying of both unstructured and structured data within a single system. By storing vector embeddings (which are mathematical representations of unstructured data like text, images, or audio) alongside traditional relational data, Oracle AI Vector Search allows users to perform semantic searches on unstructured data while also leveraging the power of SQL queries on structured business data.
This capability is particularly valuable for scenarios where organizations need to combine insights from diverse data types—such as performing a similarity search on image data while filtering results based on relational attributes like location or price. The integration also supports advanced AI techniques like Retrieval Augmented Generation (RAG), which can use both the vector embeddings and relational data to generate accurate responses to natural language queries, all while keeping private data secure.
In essence, Oracle AI Vector Search reduces the complexity and overhead of managing multiple systems for different data types and enhances the ability to derive actionable insights from a combination of unstructured and structured data.
The “Contra-Indicated” Use Case for Oracle Database 23ai Vector Search:
However, if an organization does not have existing relational data in Oracle and primarily relies on other databases, the benefits of using Oracle AI Vector Search may be less compelling [in my opinion]. In such a scenario, the complexity and overhead of migrating or duplicating data into Oracle just to take advantage of its vector search capabilities might outweigh the advantages.
Therefore, continuing to use a dedicated vector database that aligns with the organization's existing infrastructure might be more efficient and straightforward in this case. While Oracle offers advanced features like Retrieval Augmented Generation (RAG) and deep SQL integration, these may not be sufficient to justify the shift if the organization's data and infrastructure are already optimized elsewhere.
Notes for the Developer, DBA, and Architect:
Oracle Database 23ai introduces a groundbreaking feature with its vector searching capability, supported by the introduction of a new datatype called, VECTOR. This datatype can be used for columns storing vector data, allowing for advanced similarity searches and the ordering or ranking of results directly within your SQL queries. To complement this, Oracle has introduced a suite of functions tailored for similarity searching and a range of new index types specifically designed for vector columns. If you’re already familiar with indexing relational tables, you’ll find these new vector index types conceptually similar, providing more efficient queries on vector data. Additionally, Oracle has equipped the database with tools for generating vectors (embeddings) from strings or unstructured documents, importing vector embedding models in ONNX format, and managing authentication credentials for accessing third-party REST APIs. For those managing databases, there are new structures for handling vector memory pools, enhanced views for vector diagnostics, and updates to views like USER_INDEXES to include information about vector indexes.
While these capabilities are ready to be used by most Oracle developers, there is a learning curve involved. Understanding when and how to effectively use the new index types, as well as the new similarity searching functions, will be key to fully leveraging this new technology. There is lots of material out there on the exact SQL statements to use, however, in the following sections of this post, I’ll focus on the functionality and pros/cons of the design choices you’ll have for vector indexing, similarity searching among vectors, and the vector distance functions.
Vector Indexing in Oracle 23ai: Enhancing Efficiency in AI-Driven Applications
As Oracle Database 23ai introduces advanced vector search capabilities, the importance of efficient indexing cannot be overstated. Vector indexes play a crucial role in optimizing the performance of queries involving high-dimensional vector data, which is at the heart of AI-driven applications like semantic search. In this section, we’ll explore the types of vector indexes available, their memory considerations, and the restrictions you need to be aware of when implementing them.
Types of Vector Indexes
Oracle 23ai offers two primary types of vector indexes: In-Memory Neighbor Graph Vector Index (HNSW - Hierarchical Navigable Small World) and Neighbor Partition Vector Index (IVF - Inverted File Flat). The index types used by Oracle 23ai Vector Search are patterned after widely recognized design patterns in the Generative AI (GenAI) and broader machine learning industry. These design patterns are particularly focused on optimizing similarity search tasks in high-dimensional vector spaces. Further, these indexes are designed to enhance the efficiency of vector searches by reducing the search space through behind the scenes techniques like clustering, partitioning, and the use of neighbor graphs.
In-Memory Neighbor Graph Vector Index (HNSW): This index is particularly well-suited for approximate similarity searches [a kind of approximate nearest neighbor (ANN) search]. It leverages small-world network principles and hierarchical layers to structure the search process, making it highly efficient when the index can fit entirely in memory. HNSW is ideal for scenarios where speed is critical, and you can afford the higher memory usage. Further, HNSW indexes are known for their efficiency in handling high-dimensional vector data by structuring vectors in a way that makes searching faster while maintaining accuracy.
Neighbor Partition Vector Index (IVF): The IVF index offers a balance between search quality and resource usage [another industry-standard approach for ANN searches]. By partitioning the data, it allows for efficient searches while using both buffer cache and disk storage. This makes IVF a good choice when memory is limited, as it has lower RAM requirements compared to HNSW. Th IVF method is widely used in various GenAI applications where balancing search quality and computational efficiency is essential.
Memory Considerations
Efficient use of vector indexes requires careful memory planning, especially when dealing with large datasets or high-dimensional vectors. Oracle introduces the vector pool in the System Global Area (SGA), which must be enabled to use vector indexes. This pool stores the vector indexes and metadata, and its size is controlled by the vector_memory_size parameter.
Memory Allocation for HNSW Indexes: The memory required for HNSW indexes is significant, as it involves storing the entire index structure in memory. The required memory can be estimated as 1.3 times the product of the vector format size, the number of dimensions, and the number of rows. This factor accounts for overhead and additional layers in the graph structure. For example, an HNSW index on 1 million rows of vectors, each with 1,536 dimensions in float32 format, would require approximately 1.9 GB of memory.
IVF Indexes and Buffer Cache: IVF indexes, on the other hand, are more flexible with memory usage, as they can leverage both buffer cache and disk storage. This makes them suitable for larger datasets where not all data needs to be in memory simultaneously.
Restrictions and Best Practices
When working with vector indexes in Oracle 23ai, it’s important to be aware of certain restrictions:
1. Dimension Consistency: All vectors in a column indexed by a vector index must have the same number of dimensions. This is critical for the index to function correctly and for distance functions, which rely on dimension consistency.
2. Single Index Type Per Column: Only one type of vector index can be created per vector column. This means you need to choose the indexing strategy (HNSW or IVF) that best fits your use case.
3. RAC Environment Limitations: In Real Application Clusters (RAC) environments, creating HNSW indexes on non-RAC single instances is not supported. However, both HNSW and IVF indexes can be used in RAC setups, with HNSW being preferred when it can fit into memory.
The following table summarizes the qualities of the vector search index types and when to use them and when not to use them.

In summary, vector indexing is a powerful feature in Oracle 23ai that, when used correctly, can significantly enhance the performance of AI-driven applications. Understanding the types of vector indexes, their memory implications, and the associated restrictions is key to leveraging this technology effectively in your database environment.
Similarity Searching:
Oracle has packaged a set of new functions specifically designed to enable similarity (or semantic) searches on vectorized data. These functions offer various capabilities that cater to different search requirements, and understanding their nuances will be crucial in applying them effectively. The similarity searching types used by Oracle 23ai Vector Search are patterned after well-accepted design patterns in the Generative AI (GenAI) and machine learning industry, making them reliable and familiar tools/capabilities for developers working with text data and embeddings. These patterns are designed to efficiently handle high-dimensional vector data, which is essential for tasks like semantic search, recommendation systems, and natural language processing.
To assist with this, I’ve prepared a comparison table to outline the strengths and weaknesses of each function, along with recommendations on when to use or avoid them (below). Again, I will refer you to the Oracle doc’s for the exact syntax for using these search functions.

Distance Functions:
Oracle has also introduced distance functions that are pivotal for tasks involving the measurement of similarity or dissimilarity between vectors. These functions are especially important when working with high-dimensional data, as they form the mathematical foundation for many data processing tasks, allowing Oracle Database to efficiently perform complex analytical operations.
To aid your understanding of the strengths and weaknesses of the various distance functions used in similarity searching, I’ve created a detailed comparison table (below). Again, as before, I will refer you to the Oracle doc’s for the exact syntax for using these search functions.

The following graph in two-dimensional vector space illustrates the differences between three of the distance functions.
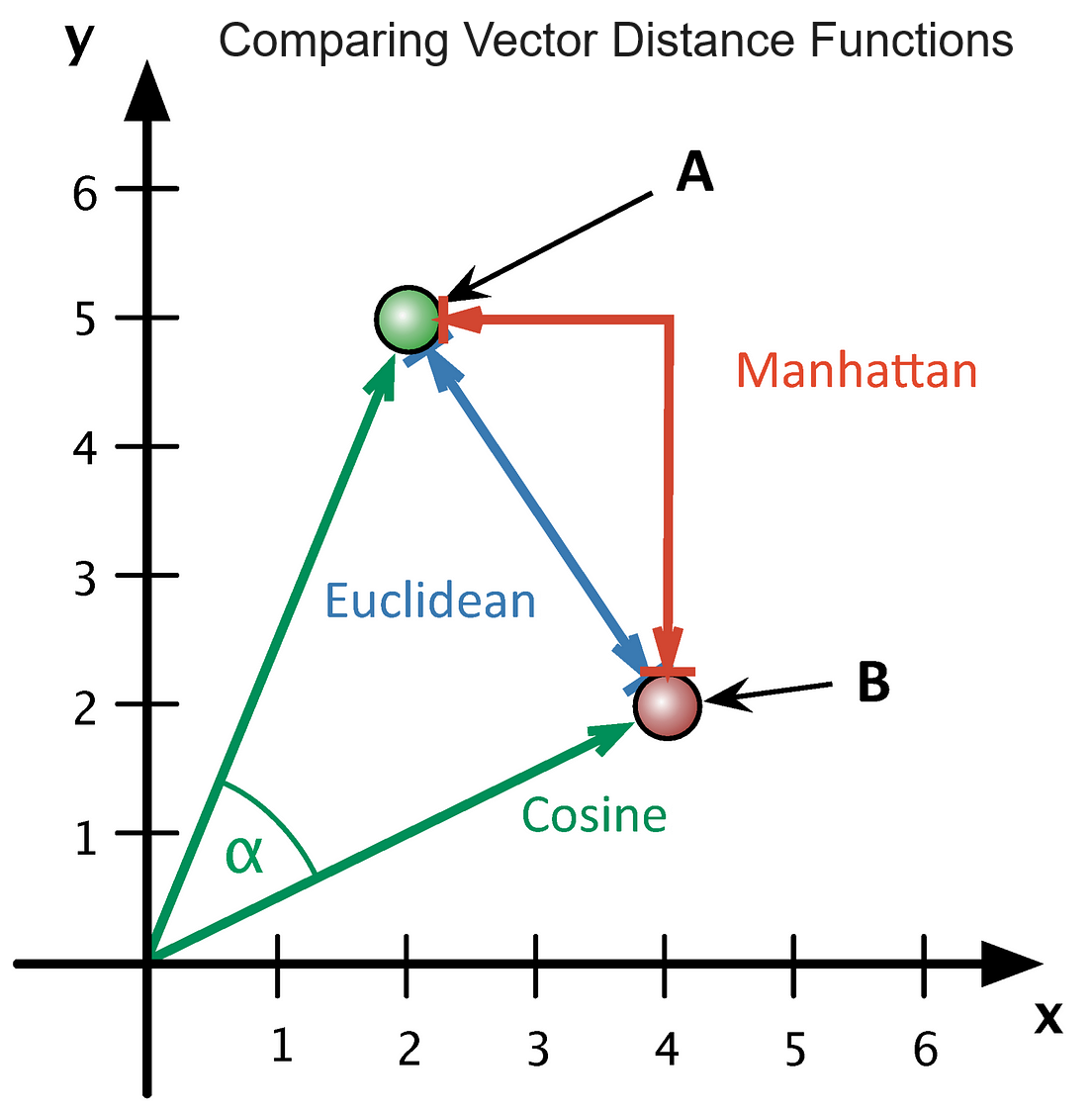
The cosine distance in two-dimensional space measures the angle between two vectors, reflecting how similar their directions are, regardless of their length. In multi-dimensional space, the cosine distance quantifies the difference in direction between two vectors, calculated as one minus the cosine of the angle between them, making it useful for comparing the orientation of high-dimensional vectors.
The Euclidean distance in two-dimensional space is the straight-line distance between two points, calculated using the Pythagorean theorem. In multi-dimensional space, the Euclidean distance is the square root of the sum of the squared differences between corresponding coordinates of two points, representing the shortest direct path between them.
The Manhattan distance in two-dimensional space is the sum of the absolute differences between the x and y coordinates of two points, as if moving along the grid lines of a city. In multi-dimensional space, the Manhattan distance is the sum of the absolute differences between the corresponding coordinates of two points across all dimensions, reflecting movement along a grid-like structure in higher dimensions.
Conclusion:
In conclusion, Oracle Database 23ai’s vector search capabilities mark a significant shift in how traditional relational database applications can evolve to incorporate the power of generative AI. For developers accustomed to working within the confines of SQL and relational data, this new functionality opens up opportunities to build more intelligent and context-aware applications directly within the database. By integrating vector embeddings, Oracle has made it possible to perform advanced tasks like semantic search, similarity matching, and ordering/ranking results without requiring external AI platforms or lots of specialized knowledge in generative AI. This means that the skills you’ve honed over years of working with Oracle SQL can now be easily extended to tackle some of the most cutting-edge challenges in AI-driven application development.
As you begin to explore these capabilities, it’s important to recognize that while the tools are new, your existing expertise in the underlying historic capabilities of SQL remain and actually can be used to enhance the quality of the output. Learning how to effectively utilize vector search functions, manage new index types, and harness the power of large language models within the Oracle ecosystem will not only enhance your current projects but also position you at the forefront of the evolving database landscape. Embrace this opportunity to expand your skillset, knowing that Oracle 23ai is designed to bridge the gap between traditional relational databases and the future of AI-powered applications, all within the SQL framework you’re already familiar with.