
Introduction:
This blog post is intended to help you tame the AWR tsunami by diving deep into the active session history (ASH). ASH data is exposed to us by Oracle in the views dba_hist_active_sess_history and gv$active_session_history (“current” data). Typically, I will query the data in ASH rather than use a standard ASH report or an AWR report; my reason for this is simple, it has been my experience that I can get at the root cause of a performance issue a lot faster by querying the data in a custom way than I can by using the standard reports. There is a case for using the standard reports, but bear in mind that they only expose the data in a certain way, which may not be suitable for any arbitrary performance case. This of course is a double-edged sword as you must now understand a bit more about what the data source contains and have a bit of creativity in the best way to use that information in a manner that suits the individual performance case that you are encountering. ASH is an incredible and detailed source of database performance metrics. It has details on the user running the SQL, when the session ran the SQL, whether it was ON CPU or WAITING, the wait events themselves, if there was a blocking session, distinct executions of a SQL statement, PGA allocation, TEMP tablespace allocation, what portion of the SQL execution plan the sample represents, and much more. There are several things to be aware of when using these views:
1. The sampling mechanism used in ASH means that some sessions/SQL don’t get sampled. In my experience it seems to be the things that run faster than 1 second that start and finish between samples can get missed. Typically though, if the SQL is run often enough it will get sampled eventually and you’ll have some trace of it in ASH.
2. The view gv$active_session_history has a sample every 1 second and is a circular memory buffer, so it will have historic data for a limited time range.
3. One out of every 10 samples from gv$active_session_history is rolled up into dba_hist_active_sess_history at each snapshot interval, therefore a row in the dba_hist version of ASH will represent about 10 seconds of time. This is not a perfect measurement, but it is the best you can get from the dba_hist version of ASH.
Questions You Can Answer with ASH:
Since ASH will have tons of session and SQL-level information including [as stated before] details on the user running the SQL, when the session ran the SQL, whether it was ON CPU or WAITING, the wait events themselves, if there was a blocking session, distinct executions of a SQL statement, PGA allocation, TEMP tablespace allocation, what portion of the SQL execution plan the sample represents, …, we can use these facts to extract the information we need for the particular performance case we are working on.
Where is my CPU going?
Another way of wording this is: Which users are contributing the most to AAS (AAS = Average Active Sessions, a common workload metric used in the Oracle database)?
The below query can be used to answer this question:
-- ASH User and Service CPU only-- =============================select username, name service_name, sum(10) "CPU (sec)"from dba_hist_active_sess_history ash, dba_users du, dba_services swhere trunc(sample_time) >= trunc(sysdate) and session_state = 'ON CPU' and du.user_id = ash.user_id and s.name_hash = ash.service_hashgroup by du.username, s.name;
Notice that I am pulling in the username and service_name by translating that from their primary key. Also, sum(10) gives us an approximation of the number of seconds on CPU since one row in ASH history more or less represents 10 seconds of time. Of course, it is best to subset the ASH data on the (hopefully small) time range that is relevant to your performance case, but I’ll leave that to the reader/learner to code in to the SQL statement.
Who is waiting the most?
The session_state is either ‘ON CPU’ or ‘WAITING’, thus you can actually see the relative proportion of CPU time versus wait time for the user. That would be an easy change to the above SQL statement:
-- ASH User and Service Wait Time-- ==============================select username, name service_name, sum(10) "WAITING (sec)"from dba_hist_active_sess_history ash, dba_users du, dba_services swhere trunc(sample_time) >= trunc(sysdate) and session_state = 'WAITING' and du.user_id = ash.user_id and s.name_hash = ash.service_hashgroup by du.username, s.name;
What SQL is waiting the most?
One can easily extend this to tell us even more by adding, say, SQL_ID to the select list and the group by clause, so that you can see the CPU or wait (or both as below) allocation by the SQL statement that the user was running. The query below gives me the top 20 long running SQL from ASH:
-- ASH User and Service Total Time on a SQL statement-- ==================================================select username, name service_name, sql_id, sum(10) "Total Time (sec)"from dba_hist_active_sess_history ash, dba_users du, dba_services swhere trunc(sample_time) >= trunc(sysdate) and du.user_id = ash.user_id and s.name_hash = ash.service_hashgroup by du.username, s.name, sql_idorder by 4 descfetch first 20 rows only;
What is the SQL waiting on?
You may find in an AWR report a top wait event of ‘db file scattered read’ or ‘enq: TX - allocate ITL entry’, or <insert random wait event here>. Developing an understanding of what these wait events mean is important to helping resolve specific issues, but since this blog post is not about a specific performance case, I’ll leave that to the reader to research from the many doc’s and blog posts having those details. You can find out which sessions are getting any wait event by querying ASH. [Typically, if I need different aggregations of ASH data, I’ll have a specialized SQL statement for that aggregation.]
A simplified version of the SQL I will normally use [extending on the model above] would look something like the following:
-- ASH Total Time on a SQL statement in what event-- ==================================================select username, name service_name, sql_id, decode(session_state, 'ON CPU', session_state, event) event, sum(10) "Total Time (sec)"from dba_hist_active_sess_history ash, dba_users du, dba_services swhere trunc(sample_time) >= trunc(sysdate) and du.user_id = ash.user_id and s.name_hash = ash.service_hashgroup by du.username, s.name, sql_id, decode(session_state, 'ON CPU', session_state, event)order by 5 desc;
Are there any other sessions blocking my SQL?
This is a very typical question which can easily be answered by a query to the ASH. We use the fact that if the column blocking_session is populated then the session/SQL is blocked. Generally, there will be a chain of wait events involved, for example, session A is waiting on ‘log file sync’ because of a system session waiting on say, ‘SYNC Remote Write’ and ‘log file parallel write’ [as in a potential case where synchronous replication to secondary database is done by Data Guard (i.e. a local session has to wait for the replication to the secondary database is complete). My usual version to check for blocked sessions is quite a long query, so not suitable for publishing here, but my colleague at Enkitec, Eduardo Claro, published a nice query for this in his blog [ https://clarodba.wordpress.com/2023/05/18/how-to-see-locks-from-ash-the-right-way/ ].
Who are the Top PGA consumers?
Have you ever encountered the dreaded "ORA-04036: PGA memory used by the instance exceeds PGA_AGGREGATE_LIMIT” error in Oracle? This error occurs when the total amount of memory used by all of the individual session PGAs (Program Global Areas) in the database instance exceeds the PGA aggregate limit (controlled by the pga_aggregate_limit initialization parameter). The pga_aggregate_limit parameter was introduced in Oracle version 12c to help applications avoid cases where PGA consumes too much memory which can cause the database host server to get into a bad memory swapping situation at the operating system level. This also gives one the opportunity to find the offending SQL and tune it if possible. Sadly, I’ve seen too often where DBA’s will just bump the limit to avoid the error, rather than use the opportunity to find the offending SQL and try tuning them or working with the application team to redistribute the workload. I call just bumping the limit as “chasing the PGA aggregate limit error”, because it is not easy to determine what the PGA requirements of a future workload will be and what the new limit should be, so if you follow this “bump” model, you’ll most likely need several “bumps” of the limit before the situation stabilizes. Tuning the SQL can include reducing the amount of data being processed, using indexes to improve query performance, and reducing the number of sorts and hash joins.
Thankfully, ASH has a column, PGA_ALLOCATED, which is the amount of PGA memory (in bytes) consumed by the session at the time the sample was taken. With this we can easily find the top PGA consumers. The following query example provides a useful starting point for DBAs or application teams looking to identify and address PGA memory consumption issues:
-- ASH Top PGA Consumers-- ==================================================select username, name service_name, sql_id, max(pga_allocated) "Max PGA Allocated"from dba_hist_active_sess_history ash, dba_users du, dba_services swhere trunc(sample_time) >= trunc(sysdate) and du.user_id = ash.user_id and s.name_hash = ash.service_hashgroup by du.username, s.name, sql_idorder by 4 descfetch first 20 rows only;
Who are the Top TEMP tablespace consumers?
The also dreaded “ORA-01652: unable to extend temp segment by <> in tablespace TEMP” error occurs when Oracle is unable to allocate more space in the temporary tablespace for a particular operation, such as sorting or joining large data sets. This error typically indicates that the temporary tablespace is running out of space, and Oracle cannot extend it further to accommodate the operation. I should note that sometimes a SQL statement is the “victim” of the error rather than the cause for the error (i.e. a SQL needed a small amount of temp, but someone else was using most of it), so it is, in my view, necessary to find out who are the top TEMP tablespace consumers, especially if TEMP is already big and it makes more sense to tune the SQL rather than just increasing TEMP.
Using the TEMP_SPACE_ALLOCATED column in ASH (which is the mount of TEMP tablespace (in bytes) consumed by the session at the time the sample was taken) to identify top temporary tablespace consumers is a practical approach to begin addressing this issue. Of course, DBAs can increase the temporary tablespace size if the temporary tablespace is running out of space frequently, but sometimes it is necessary to review and optimize SQL statements that are using a large amount of temporary tablespace. The following query example provides a useful starting point for DBAs or application teams looking to identify and address TEMP tablespace consumption issues:
-- ASH Top TEMP Consumers-- ==================================================select username, name service_name, sql_id, max(temp_space_allocated) "Max TEMP Space Allocated"from dba_hist_active_sess_history ash, dba_users du, dba_services swhere trunc(sample_time) >= trunc(sysdate) and du.user_id = ash.user_id and s.name_hash = ash.service_hashgroup by du.username, s.name, sql_idorder by 4 desc nulls lastfetch first 20 rows only;
Miscellaneous Tips:
Again, ASH is a rich source of information, when used wisely will yield fantastic insights into your performance evaluations. There are many more questions regarding query performance that can be answered using ASH data. Of course it is not practical to cover every question, so I leave further exploration to the reader. I will however, leave you with a few miscellaneous tips I have used with respect to ASH data.
SQL Arrival Times
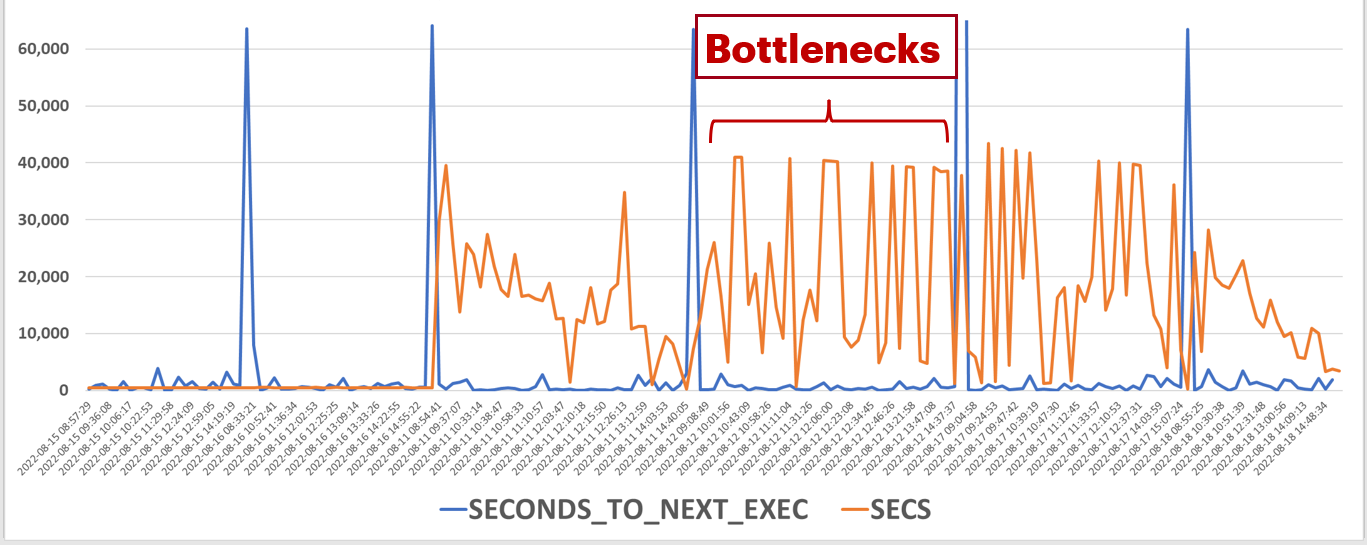
Knowing the SQL arrival times can help in troubleshooting performance issues. For example, if SQL is coming in faster than it can be processed, you’re going to have a bottleneck. In the following query, I am calculating the seconds to the next execution of the query and comparing that to the query duration. The bottleneck is when the query duration is much greater than the seconds to the next execution of the query. There are a few things to know about the ASH columns:
· The SQL_EXEC_START column is the time when the execution of the SQL started
· The SQL_EXEC_ID column is the individual execution of a SQL statement
By using the LEAD function, as below, I can get the number of seconds until the next execution of the query. Finally, I’m flagging the times when the seconds to the next execution of the query was less than the query duration.
with ash as select sql_id, sql_plan_hash_value, ((lead(sql_exec_start) over (order by sql_exec_id) - sql_exec_start ) * (24*60*60)) seconds_to_next_exec, sum(10) secs, sql_exec_start as sql_exec_start_time from dba_hist_active_sess_history a where sql_exec_start >= trunc(sysdate-nvl(:days_back, 0)) and SQL_ID = 'g7pa3kp7524ha' and sql_exec_id is not nullgroup by sql_id, sql_plan_hash_value, sql_exec_id, sql_exec_start)select ash.*, case when seconds_to_next_exec < secs then '*******' end flagfrom ash order by sql_id, sql_exec_start_time ;
A graphed-out example of this follows:
How to identify which application component is invoking the SQL:
In Oracle's Active Session History (ASH), the ACTION column typically contains information about the action being performed by the session at the time of the sample. This information is set by the application (via call to the package DBMS_APPLICATION_INFO) and can be used to identify which application component or module is invoking the SQL statement.
When the application sets the ACTION column appropriately, it can provide valuable insights into the source of the workload. For example, in a web application, the ACTION column might contain the name of the web page or service that is generating the SQL statements. In a batch processing application, it might contain the name of the batch job or process.
By analyzing the ACTION column in ASH, you can:
1. Identify Application Components: You can see which parts of your application are generating the most workload and causing the most database activity.
2. Troubleshoot Performance Issues: If a particular application component is causing performance problems, you can use the ACTION column to narrow down the issue and focus your tuning efforts.
3. Optimize Resource Usage: Understanding which application components are generating the most SQL statements can help you optimize resource usage and improve overall application performance.
It's important to note that the ACTION column is only useful if the application is properly setting it. If the ACTION column is not set or is set incorrectly, it may not provide accurate information about the application components. Therefore, it's essential to work closely with your application developers to ensure that the ACTION column is set correctly and consistently across your application.
Conclusion and What’s next?
ASH analytics is just the tip of the iceberg in relation to all the AWR data available to you, and I hope that I have whet your appetite for further exploration. As William Butler Yates put it: “Education is not the filling of a bucket, but the lighting of a fire.” In future posts I hope to continue to stimulate your interest in diving deep into AWR metrics and thereby help you tame the AWR tsunami. There are many other very important sources of AWR data to explore, such as dba_hist_sqlstat (aggregate performance metrics for SQL statements). The next blog will help you tame the AWR tsunami by diving deep into dba_hist_sqlstat.