In Part 1 of this series, I introduced the concept of querying the underlying Advisor views with the purpose of scaling up your tuning capability.
In Part 2, I explained what the Advisor Framework is and why you would want to scale-up your use of the Advisor Framework.
Part 3 was about the view structure for the Advisor framework and provide a description as to what is stored in the Advisor tables.
Part 4: Querying the advisor framework
In this post I describe and provide various useful queries against various Advisor views. This is intended to give you the essence of the content of these key Advisor views. I will start off with some simple queries and then progress in Part 5 to some queries that are a bit more complicated.

Simple query on DBA_ADVISOR_FINDINGS
This is a simple example that will point you to something akin to the “biggest problem” identified by ADDM. This is not typically how I query the Advisor framework, but I use it here as an example usage; I’ll get to more complex and useful queries subsequently. Here’s the query and, as Jeff Smith says, “Just jump me to the code” [not an exact quote].
select * from (select round((ratio_to_report(max(impact)) over () *100)) as pct_impact_overall, finding_name, type, min(impact) min_impact, max(impact) max_impact, impact_type, count(*)from DBA_ADVISOR_FINDINGS where impact_type is not nullgroup by impact_type, finding_name, type)where pct_impact_overall >=5 order by pct_impact_overall desc ;The following is an example of running the above query on a production database, ordered by the percent impact overall calculation which is using the maximum impact (measured in microseconds of database time).
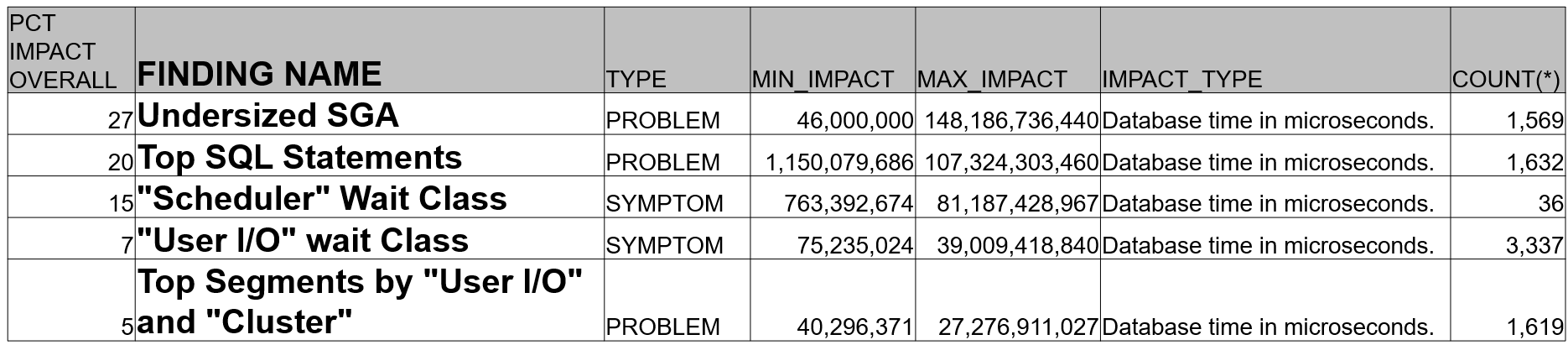
In this case it shows that an undersized SGA is the top ADDM finding by the impact on the system. Notice also the last count(*) column – even though user IO wait class was in more ADDM analyses (over 3000), the percent overall impact is lower; perhaps fixing that symptom or lowering its impact may be accomplished by increasing the SGA. Basically, I’ll use this kind of information found in the Advisor framework to inform [not direct] the tuning action plan. The reasoning is that you shouldn’t hang your hopes on a single silver bullet fix, but rather use all the database metrics to support your root cause analysis and use the Advisors to help flesh out your tuning action plan.
Another example usage of the “biggest problem” query is that you can use the high-level findings to quickly highlight possible problems. Consider the two databases in the image below.

The pie charts above show that the “biggest problem” on USPRD025 is undersized SGA finding whereas on USPRD011 the Biggest problem is in the User I/O wait Class finding.
Simple query on DBA_ADVISOR_RECOMMENDATIONS
This next example provides something akin to the “main recommendations” identified by ADDM and other advisors. Again, this is not typically how I query the Advisor framework, but I use it here as an example to show the content of this view. Here’s the query:
select round((ratio_to_report(max(Benefit)) over () *100)) as overall_benefit_pct, type, min(benefit) min_benefit, max(Benefit) max_benefit, count(*) cntfrom dba_Advisor_recommendations where type is not null group by type order by 1 desc ;The following output is an example of running the above query on a production database, ordered by the percent impact overall calculation which is using the maximum impact (again measured in microseconds of database time).

In examining the output, I see segment tuning coming up as a high benefit recommendation as well as the others pointed out. So essentially, the next steps would be to see which segments require tuning, or perhaps the segment tuning advisor was already run on these objects and that information can be mined as well.
Simple query on DBA_ADVISOR_ACTIONS
This next example provides something akin to the “main recommendations” identified by ADDM and other advisors. Again, this is not typically how I query the Advisor framework, but I use it here as an example to show the content of this view. Here’s the query:
select command, message , count(*) from dba_advisor_Actionsgroup by command, message ;The following output is an example of running the above query on a production database.

The main thing that I wanted to point out with DBA_ADVISOR_ACTION is how detailed the actions are. In my experience, the advisor actions provide a wealth of information, again to inform your tuning action plan. So essentially, the next steps would be to see if these recommended actions align with the reported performance problem; after all, the ADDM advisor for example is only looking at the top SQL, which may or may not be the SQL that your users are complaining about.
What’s next:
I hope these examples have piqued your interest in running queries against the DBA_ADVISOR views. In the upcoming Part 5 I will provide several case studies of the Advisor framework in use (i.e. the way I would generally query the Advisor framework data for problem solving), and hopefully further illustrate how useful these custom queries are.
Series Outline
If you have been following along. there is a lot of content in this topic, and I’m breaking up the blog posts up into a more easily digestible 6-part series.
Part 1: Series Introduction
The Series Introduction is Part 1, where I introduce the concept of querying the underlying Advisor views with the purpose of scaling up your tuning capability.
Part 2: What is the Advisor Framework?
In Part 2, I wrote on what the Advisor Framework is and why you would want to scale-up your use of the Advisor Framework.
Part 3: Advisor tables structure.
Part 3 was about the view structure for the Advisor framework and provide a description as to what is stored in the Advisor tables.
Part 4: Querying the advisor framework
In Part 4, (this post) I describe and provide various useful queries against various Advisor views. This is intended to give you the essence of the content of several key Advisor views.
Part 5: Case Studies / Advisor framework in use
In Part 5, I will provide several case studies of the Advisor framework in use, and hopefully show how useful these custom queries are.
Part 6: Jet Tour Through the Catalog of SQL Tools
In the last part of the series, I plan to provide a catalog of the SQL tools I’ve developed. The SQL I use is in the public domain.
Update Your Bag-Of-Tricks
Again, stick around for this month’s series and get actual working SQL code to put in your bag-of-tricks, and hopefully use and improve your Oracle database tuning skills.
I like the bag-of-tricks motif because it reminds me that, as a kid, I was impressed by Felix the Cat (cartoon character) [I guess I’m dating myself and admitting I watched too much TV]. Felix would get himself into some kind of trouble, and at the last moment he would reach into his bag-of-tricks and come up with a solution to save the day. Early in my Oracle career [goes back to Oracle V4 in 1985], I would learn of various SQL queries against the data dictionary and other ways to work your way through what’s going on under the covers in Oracle. I was struggling for what to call the directory where I kept this code, a light bulb goes on and I decided on using Felix’s bag-of-tricks as a metaphor. So, all new capabilities for introspecting the database, documents, … go into my bag-of-tricks.
