Summary
“In the practice of performance tuning, change is inevitable. New techniques are created; old ones are updated. … To survive and thrive in [the field of performance tuning], innovation is everything. Nothing remains the same for long. We either innovate and adapt to change or change happens to us.” [Roger Cornejo, 2018, Dynamic Oracle Performance Analytics]. The Dynamic Oracle Performance Analytics (DOPA*) method I developed, innovates by leveraging feature selection and feature engineering [concepts and practices commonly used in the field of data science]. Simply put (and for the purposes of analyzing performance metrics), the concept of feature engineering [aka feature extraction] is leveraged by creating or transforming data into metrics that can go into the analysis model that identifies performance anomalies. In the DOPA process, I implement feature engineering when I unpivot (using SQL) the short/wide multi-column tables of metrics into the tall/skinny Key-Value (KVP) pair structure, which I refer to as “KVP normalization”; You may ask, what is Feature Engineering? … Feature engineering is essentially building up your set of metrics to analyze. The technique of unpivoting the data from the multi-column format to the key-value-pair structure is a vitally important to my practice because it allows me to easily scale my analysis to tens of thousands of metrics [for database level metrics, I have literally instrumented tens of thousands of different metrics for analysis to determine their impact on the performance “equation” (i.e. the model)]. While feature engineering allows me to scale up the set of metrics to analyze, I use the concept of feature selection to reduce or remove from the model, features (metrics) that don’t add to the model’s understanding; thus, feature selection results in a more manageable set of that metrics that are the key influencers in the performance problem at hand. In the DOPA process, I implement feature selection in plain SQL by means of statistical anomaly detection, focusing in on metrics that are outside of their normal range.
SQL Level Metric Analysis
I have presented on the DOPA process [i.e. the topic of the book] at technical conferences on many occasions and one of the most consistent questions I get is: Can I apply this process to SQL-Level analysis? The answer to this is, “Yes”; I have written the “alpha release” code for this (which is already in the public domain – contact me if you’re interested), and I’m basing my further work on dynamic SQL-level analysis of performance metrics on this alpha release. In subsequent posts, I will walk through in detail (with SQL examples) into how feature engineering and feature selection is used to analyze SQL statement level Oracle performance metrics found in the Automated Workload Repository (AWR) views for active session history and SQL statistics.
The Problem and the Solution
The Problem
A problem that is often encountered in SQL-level analysis is finding out what changed to make the SQL run slower. Since the SQL-level performance metrics are scattered across multiple columns in multiple tables, it is often difficult to zero in on the set of metrics that most influenced the “performance equation”.
The Solution
I extended the DOPA process to SQL-level analysis by engineering features (essentially all the metrics) from DBA_HIST_ACTIVE_SESS_HISTORY and DBA_HIST_SQLSTAT. Further, the statistical anomaly detection mechanism (feature selection) of the DOPA process zeroes right in on the relevant metrics that represent the key influencers in the performance problem at hand.
*DOPA: I. Dynamic Approach – Intro
For a comprehensive background in the Dynamic Oracle Performance Analytics (DOPA) process, I would refer to the short medium article Analytics Using Feature Selection for Anomaly Detection or my book: Dynamic Oracle Performance Analytics: Using Normalized Metrics to Improve Database Speed. For some brief context here: the DOPA method I developed is basically a statistical anomaly detection mechanism [implemented using SQL alone] that represents a step-change paradigm shift away from traditional methods of analysis which tend to rely on a few hand-picked metrics [for this reason, I call them small-model approaches]. Generally, traditional metric-by-metric approaches have metric specific code which makes it nearly impossible to scale traditional methods to the tens of thousands of metrics available in the Automated Workload Repository (AWR). Through a clever use of one-hot encoding, for every snapshot interval I assign a 1 to a metric value if it is outside the normal range or I assign a 0 to the value if it is within the normal range; thus, all the metrics with a 1 assigned are anomalies. I further aggregate the results, by counting the number of snapshot intervals where a metric value was anomalous. Applying the concept of feature selection, the metrics with the most anomalies are the key influencers key influencers in the performance problem at hand. In using this dynamic approach to anomaly detection, I have less bias in my analysis and since I’ve instrumented more than 11,000 metrics, the DOPA process can help you determine the root cause analysis to many more problem types than the traditional, small-model, approaches can.
Feature Engineering in Action
In general, to engineer features into your model, one would use their knowledge of the problem domain to pick the metrics. In this post I’ll touch on a few examples of feature engineering as applied to SQL-level metrics found in DBA_HIST_SQLSTAT. In subsequent posts, I’ll cover feature engineering as applied to SQL and session-level metrics the active session history, DBA_HIST_ACTIVE_SESS_HISTORY.
As many DBA’s familiar with Oracle tuning will know the view DBA_HIST_SQLSTAT which is used to expose the SQL-level metrics collected by the AWR for every snapshot period.
MCT View of SQLSTAT Metrics
Below, I have, as an example, a simple select on the multi-column table (MCT) version dba_hist_sqlstat for a sql_id. For the purposes of my dynamic metric analysis method, I do not want to leave the metrics in this column-by-column/metric-by-metric format because it is much to cumbersome because any comparison I do, whether calculated (as I do in the DOPA process) or visual, will also have to be column-by-column/metric-by-metric. Thus, with data in the MCT format, it is difficult to scale column-by-column analysis to many metrics.

I’ve taken a screenshot (below) of the data values produced after running the above query on select DBA_HIST_SQLSTAT columns. I’m showing this impossible to read version to emphasize the point of trying to deal with many columns in the multi-column table format, typical of AWR metrics.

The following is a bit easier to read, but I don’t see all the columns.

Sidebar Note: You may have noticed that I don’t use the cumulative %_TOTAL columns, that is because in my experience it is easier to interpret the metrics values for performance analysis when we are looking at the change in the values for a metric in a snapshot period (i.e., the %_DELTA columns).
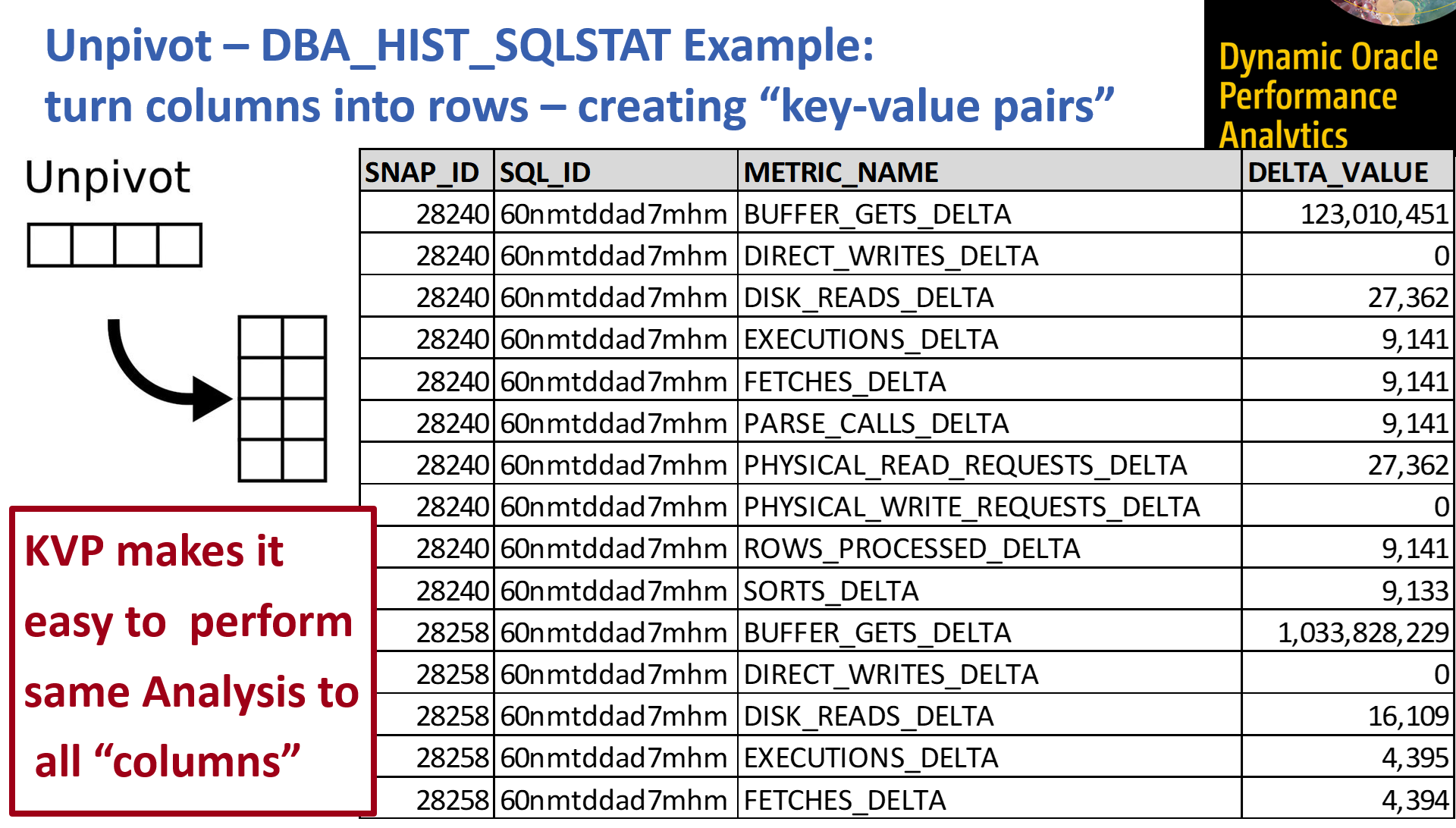
KVP View of SQLSTAT Metrics
The following SQL can be used to unpivot the multi-column table version of DBA_HIST_SQLSTAT to the Key-Value-Pair “view”. This may seem complicated, but a discerning evaluation will find that I’m doing some additional feature engineering by computing the times out to seconds, the bytes out to megabytes, and labeling the metrics that are counts. I’m also fixing a “problem” with the data and an assumption with my DOPA process by multiplying some values by -1. I plan to go into this in more detail in a future post but suffice it to say, most metrics are instrumented such that the larger the value, the worse the performance condition. For example, a high number of buffered gets is usually worse than a low number of buffered gets. With Exadata, high values for the metrics related to cell/IO offloading, etc. are (in my interpretation) a good thing [please feel free to offer your interpretation of these metrics]; thus, I am multiplying these values by -1 as a short-hand way of keeping the anomaly detection calculations the same for all metrics/values.
column metric_name format a70with sqlstat as /* get all the SQLSTAT data of interest ; unpivot later */(select SNAP_ID,SQL_ID,PLAN_HASH_VALUE,FETCHES_DELTA,END_OF_FETCH_COUNT_DELTA,SORTS_DELTA,EXECUTIONS_DELTA,PX_SERVERS_EXECS_DELTA,LOADS_DELTA,INVALIDATIONS_DELTA,PARSE_CALLS_DELTA,DISK_READS_DELTA,BUFFER_GETS_DELTA,ROWS_PROCESSED_DELTA,CPU_TIME_DELTA,ELAPSED_TIME_DELTA,IOWAIT_DELTA,CLWAIT_DELTA,APWAIT_DELTA,CCWAIT_DELTA,DIRECT_WRITES_DELTA,PLSEXEC_TIME_DELTA,JAVEXEC_TIME_DELTA,IO_OFFLOAD_ELIG_BYTES_DELTA,IO_INTERCONNECT_BYTES_DELTA,PHYSICAL_READ_REQUESTS_DELTA,PHYSICAL_READ_BYTES_DELTA,PHYSICAL_WRITE_REQUESTS_DELTA,PHYSICAL_WRITE_BYTES_DELTA,OPTIMIZED_PHYSICAL_READS_DELTA,CELL_UNCOMPRESSED_BYTES_DELTA,IO_OFFLOAD_RETURN_BYTES_DELTAfrom dba_hist_sqlstatwhere 1=1 /* in practice you will subset on the snapshots of interest */ and sql_id = '988a1hx9zc5rr'), unpivot_sqlstat_counts as /* SQLSTAT: "total <metric_name> (count)" */(select sql_id, snap_id, 'total ' || lower(substr(metric_name, 1, length(metric_name)-6)) || ' (count)' metric_name, case when metric_name like 'OPTIMIZED_PHYSICAL_READS%' then sum(delta_value) * -1 else sum(delta_value) end as delta_valuefrom (select sql_id, snap_id, metric_name, delta_valuefrom sqlstatunpivot include nulls( delta_value for metric_name in(FETCHES_DELTA,END_OF_FETCH_COUNT_DELTA,SORTS_DELTA,EXECUTIONS_DELTA,PX_SERVERS_EXECS_DELTA,LOADS_DELTA,INVALIDATIONS_DELTA,PARSE_CALLS_DELTA,DISK_READS_DELTA,BUFFER_GETS_DELTA,ROWS_PROCESSED_DELTA,DIRECT_WRITES_DELTA,PHYSICAL_READ_REQUESTS_DELTA,PHYSICAL_WRITE_REQUESTS_DELTA,OPTIMIZED_PHYSICAL_READS_DELTA)))group by sql_id, snap_id, metric_name), unpivot_sqlstat_times as /* SQLSTAT: "total <metris_name> (sec)" */(select sql_id, snap_id, 'total ' || lower(substr(metric_name, 1, length(metric_name)-6)) || ' (sec)' as metric_name , sum(delta_value)/(1000000) delta_valuefrom (select sql_id, snap_id, metric_name, delta_valuefrom sqlstatunpivot include nulls( delta_value for metric_name in(CPU_TIME_DELTA,ELAPSED_TIME_DELTA,IOWAIT_DELTA,CLWAIT_DELTA,APWAIT_DELTA,CCWAIT_DELTA,PLSEXEC_TIME_DELTA,JAVEXEC_TIME_DELTA)))group by sql_id, snap_id, metric_name), unpivot_sqlstat_bytes as /* SQLSTAT: "totals <metric_name> (meg)" */(select sql_id, snap_id, 'total ' || lower(substr(metric_name, 1, length(metric_name)-12)) || ' (meg)' metric_name , case when regexp_like(metric_name,'IO_OFFLOAD_ELIG*|CELL_UNCOMPRESSED*|IO_OFFLOAD_RETURN*') then (sum(nvl(delta_value,0))/(1024*1024)) * -1 else sum(nvl(delta_value,0))/(1024*1024) end as delta_valuefrom (select sql_id, snap_id, metric_name, delta_valuefrom sqlstatunpivot include nulls( delta_value for metric_name in(IO_OFFLOAD_ELIG_BYTES_DELTA,IO_INTERCONNECT_BYTES_DELTA,PHYSICAL_READ_BYTES_DELTA,PHYSICAL_WRITE_BYTES_DELTA,CELL_UNCOMPRESSED_BYTES_DELTA,IO_OFFLOAD_RETURN_BYTES_DELTA)))group by sql_id, snap_id, metric_name), union_sqlstat_data as /* UNIONing SQLSTAT Data */(select sql_id, snap_id, metric_name, delta_value from(select sql_id, snap_id, metric_name, delta_value from unpivot_sqlstat_countsunionselect sql_id, snap_id, metric_name, delta_value from unpivot_sqlstat_timesunionselect sql_id, snap_id, metric_name, delta_value from unpivot_sqlstat_bytes))select sql_id, snap_id, metric_name, delta_value from union_sqlstat_dataorder by sql_id, snap_id, metric_name;
I’ve taken a screenshot of the data values produced after running the above query which unpivots select DBA_HIST_SQLSTAT columns. This is what I call the KVP format where for each snapshot interval and sql_id I have a metric_name (the key) and the value for that interval. With the data logically (i.e. no physical data transformation was done) in the KVP format it is much easier compute on and compare the KVP metric values from the interval where the problem occurred to the normal interval; basically I can do the comparison using one expression rather than n expressions (where n is this number of metrics instrumented - in this example ~30 metrics). Hopefully you are beginning to get a sense for how this technique allows me to easily scale the comparative analysis to many metrics.

What’s Next?
There is too much material to present in one blog post, so I intend on fully covering the topic of applying the DOPA process to SQL-level metrics in future posts. In these upcoming posts I intend to deep dive and elaborate further on the need for dynamic SQL-level analysis; I will get into some nitty gritty on the kinds of relevant feature engineering techniques, such as unpivoting, creating new features with calculated values, and converting date/time variables to new discreet metrics that can be computed on more easily; including metrics from the active session history. I will also likely touch on some issues I encountered with interpreting tendencies in data values. Of course, in the practice of building performance tuning models, there will always be some further improvements I’d like to try out, so I plan to go into those futures as well, such as, how can we include non-numeric column values for instance: the sql plan hash value; sql plan step/operation/options; P1,P2,P3 and their text; object#/file#/block#. And finally, I plan to go through a relatively detailed jet tour of the SQL I used to perform this dynamic SQL-level performance analysis.
Thank you for your time and I hope you found this information useful. Stay tuned for more details.
