Inference in this case is the process of using pre-trained and/or fine-tuned pre-trained Generative AI models to generate output based on your input prompts.
Hosting Generative AI Applications in OCI:
Oracle has made it easy for customers to build and deploy generative AI applications.
Basically, you have two payment options for doing generative AI inferencing in OCI: 1) on-demand inferencing, and 2) setting up hosting of a dedicated AI cluster.
Why would you choose On-Demand vs Dedicated AI Cluster for inference?
I would say that the dedicated AI cluster would be best suited to a production implementation of a GenAI application where you have a good understanding of your workload and the workload is high-volume, whereas the on-demand mechanism is best suited to scenarios where you are in application development or POC (basically, variable or undefined workloads).
There are a few nuances to consider as well: costs, access to custom models, and privacy/security.
Costs:
On-demand is costed per each inference call (input and response) based on its size. Since there is no minimum commitment, you could save money with this option. On the other hand, dedicated AI clusters require a minimum commitment of 1 months’ worth (744 hours) of compute.
Pricing is based on the model you are using:
The larger models require more compute, and therefore, are more expensive. This is where a good understanding of how to pick your foundation models comes into play [I hope to have a future post on this topic]. Here’s a breakdown of pricing [at the time of this writing] for running inference apps on OCI Generative AI for on-demand usage vs dedicated AI clusters:
On-Demand Summary: You pay per character in inference calls to foundation models (not custom fine-tuned models) for both input and response. Examples of on-demand pricing (per 10,000 characters):
Ø Large Cohere: $0.0219
Ø Large Meta: $0.015
Ø Small Cohere: $0.004
Dedicated AI Hosting Cluster Summary: minimum commitment of 744 unit-hours per cluster to use foundation models and your customizations. Examples of dedicated AI cluster pricing (per AI unit-hour):
Ø Large Cohere: $24.00
Ø Large Meta: $12.00
Ø Small Cohere: $6.50
You would have to do your own head-to-head pricing analysis based on your workload needs [and data security requirements], but, for example, if a development team churned through around a 1 billion characters of input and response using the Large Cohere model [let’s say that turns out to be around ¼ million pages of results], that would cost just over $2,000 per month, whereas, to run the small Cohere model in a dedicated AI Cluster for a month it would be over $4,000.
Custom Models:
For use cases where you need a custom fine-tuned model, a dedicated AI cluster is the way to go because the on-demand access only provides the standard pre-trained models, not custom models.
Privacy/Security:
The on-demand access is on infrastructure (secure cluster) that is shared with other tenants [you provide security at your tenancy level via AIM, private network, encryption, etc], so you would probably not want to use this for sensitive workflows. Conversely, the dedicated AI clusters is an isolated non-shared compute environment [I guess that’s why there is a minimum commitment of 1 months’ worth of compute], so your sensitive workloads are better hosted here.
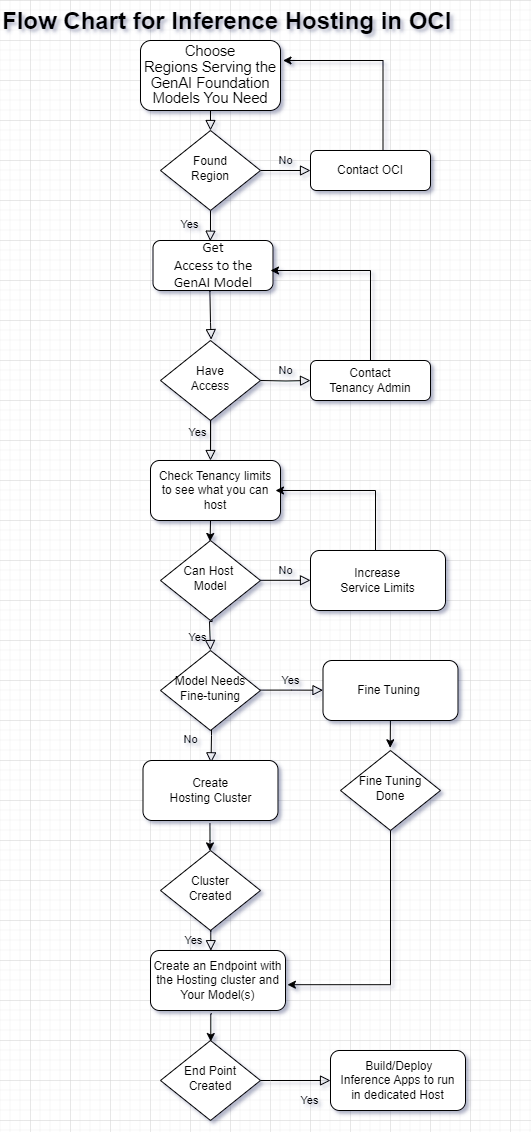
A Flowchart for Setting up Hosting Your GenAI Inference Models in OCI
The oversimplified basic workflow for setting up hosting of a dedicated AI cluster is:
1. Create a dedicated AI cluster (hosting cluster).
A dedicated AI cluster in OCI is a single tenant GPU deployment where the GPUs only host custom models or standard models that the client subscribes to, ensuring consistent model throughput as well as privacy/security through model/data isolation. -- can host one base model endpoint, and up to 50 fine-tuned custom model endpoints. There are two types of dedicated clusters:
a. Fine-Tuning Cluster: Used for training a pre-trained foundational model. In OCI, the price for this is based on the unit size needed for training and the number of hours the fine-tuning is running.
a. Hosting Cluster: Used for hosting custom model endpoints for inference. In OCI, the price for this is based on the unit size needed for hosting and by the month (min commitment is for one month
2. Create the model endpoint.
The URL interface through which models hosted on a hosting cluster can be accessed for inference input/output, thus allowing you to build applications using the endpoint.
- Reducing Inference Cost: - Definition: Sharing the same GPU resource among base and custom models, reducing the expenses associated with inference.
endpoints can be activated/deactivated through the IAM policies.
3. Serve the inference traffic or production load using the model.
- Inference Serving with Minimal Overhead: - Definition: Using parameter sharing among models derived from the same base model to reduce memory overhead when switching between models, resulting in minimal overhead.
The more detailed workflow is:
0) Choose Regions Serving the GenAI Foundation Models You Need
Pretrained Foundational Models in Generative AI (oracle.com)
1) Get Access to the GenAI Model
Getting Access to Generative AI (oraclecloud.com)
2) Check your Tenancy limits to see what you can host
3) Use Existing Pre-Trained Model or create a custom model by Fine-Tuning an Existing model
4) Create a Dedicated AI Cluster for hosting the Model(s)
Creating a Dedicated AI Cluster in Generative AI for Hosting Models (oraclecloud.com)
5) Create an Endpoint with the Hosting cluster and Your Model(s)
Creating an Endpoint in Generative AI (oraclecloud.com)
6) Build/Deploy Inference Apps to run in the Dedicated Host
Integrating the Models in Generative AI (oraclecloud.com)
7) Have fun
The Flowchart: